실습 파일 불러오기
프롬프트에서 아래의 pip 명령을 통해 패키지를 설치한다.
> pip install -U pandas-profiling
실습을 위해 아래의 링크에서 spam.csv 파일을 다운받는다.
https://www.kaggle.com/uciml/sms-spam-collection-dataset
SMS Spam Collection Dataset
Collection of SMS messages tagged as spam or legitimate
www.kaggle.com
주피터 노트북에서 아래의 코드로 spam.csv파일을 data에 저장한다.
import pandas as pd
import pandas_profiling
data = pd.read_csv(r'C:\Users\Desktop\spam.csv',encoding='latin1')
5개의 데이터만 출력해보자.
여기서 v1열 ham이라면 정상적인 메일을 의미하고, spam은 스팸 메일을 의미한다.
v2열은 메일의 본문을 담고 있다.
data[:5]
리포트 생성하기
아래의 명령어로 데이터 리포트를 생성할 수 있다.
data.profile_report()
바로 주피터 노트북에 리포트를 생성하지 않고, pr에 저장한 후 html파일로 저장할 수도 있다.
pr = data.profile_report()
pr.to_file('./pr_report.html')
리포트 살펴보기
1. 개요(overview)
Overview는 데이터의 전체적인 개요를 보여준다.
데이터의 크기, 변수의 수, 결측값(missing value) 비율, 데이터의 종류는 어떤 것이 있는지를 볼 수 있다.

해당 데이터는 총 5,572개의 샘플(행)을 가지고 있으며, 5개의 열을 가지고 있다.
하나의 값을 셀이라고 하였을 때, 총 5,572 × 5개의 셀이 존재하지만 그중 16,648개(59.8%)가 결측값(missing values)으로 확인된다.
2. 변수(Variables)
변수(Variables)는 데이터에 존재하는 모든 특성 변수들에 대한 결측값, 중복을 제외한 유일한 값(unique values)의 개수 등의 통계치를 보여준다. 또한 상위 5개의 값에 대해서는 우측에 바 그래프로 시각화한 결과를 제공한다.

앞서 개요에서 봤듯이 Unnamed라는 이름을 가진 3개의 열 모두 99% 이상의 값이 결측값인 것을 확인할 수 있다.
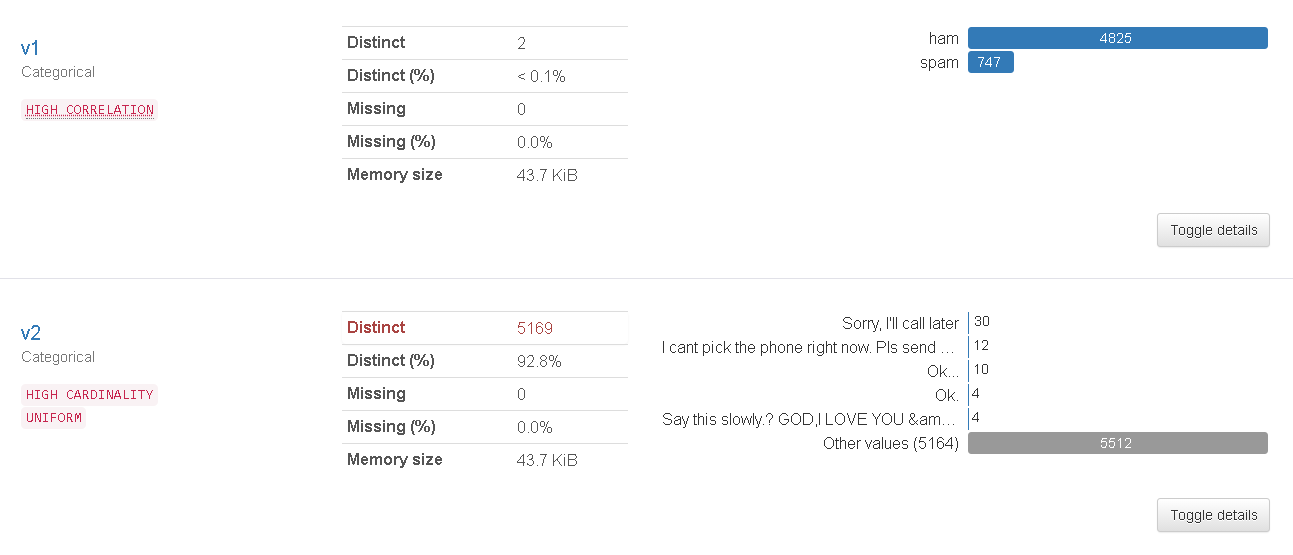
v2는 메일의 본문이고, v1은 해당 메일이 정상 메일(ham)인지, 스팸 메일(spam)인지 유무가 기재되어 있다.
v1의 경우 유일한 값의 개수(distinct count)가 2개뿐으로 5,572개의 값 중에서 우측의 바 그래프를 통해 4,825개가 ham이고 747개가 spam인 것을 알 수 있다. 이는 데이터에서 정상 메일 샘플이 훨씬 많다는 것을 보여준다.
v2의 경우 5,572개의 메일 본문 중에서 중복을 제외하면 5,169개의 유일한 내용의 메일 본문을 갖고 있다. 그중 중복이 가장 많은 메일은 Sorry, I'll call later라는 내용의 메일로 총 30개의 메일이 존재한다.
3. 상세 사항 확인하기(Toggle details)
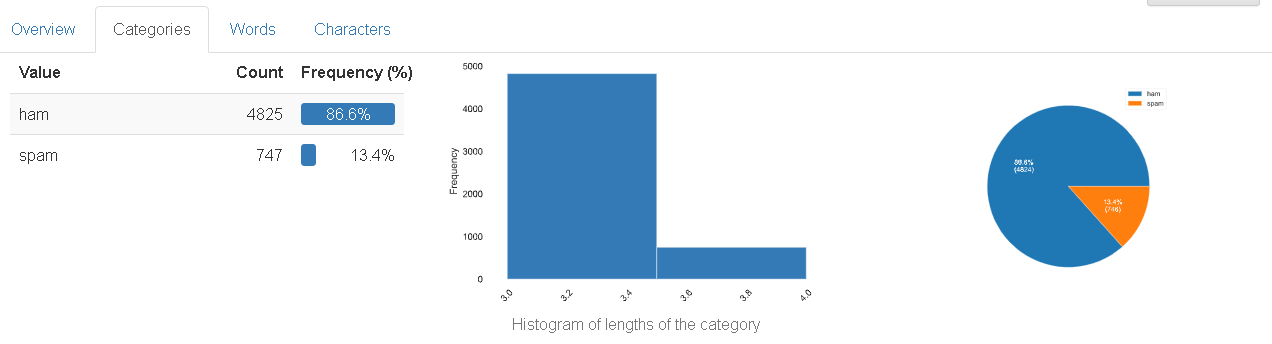
v1의 상세사항 확인하기(Toggle details)를 누른 결과는 위와 같다. 상세사항 확인하기에서는 여러 개의 탭이 존재하는데, 그중 카테고리(Categories)에서는 앞서 바 그래프로 확인했던 각 값의 분포를 좀 더 상세하게 보여준다. v1의 경우, ham이 총 4,825개로 이는 전체 값 중 86.6%에 해당되며, spam은 747개로 전체 값 중에서는 13.4%에 해당된다.

개요(Overview)탭의 맨 첫 번째 표에서는 전체 값의 최대 길이, 최소 길이, 평균 길이와 값의 구성에 대해서 볼 수 있다. v1의 모든 값들은 spam 또는 ham이라는 1개 단어만 존재하지만, 여기서의 길이는 단어 단위로 측정한 길이가 아니라 문자열 길이므로 spam의 길이인 4가 최대 길이(max length)가 되고, ham의 길이인 3이 최소 길이(min length)가 된다. 4,825개의 4의 길이를 가진 값과 747개의 값의 3의 길이를 평균 길이는 3.134063173이다. 또한 v1열의 모든 값들은 숫자, 공백, 특수 문자 등이 없이 알파벳만으로 구성되므로 Contains chars에서만 True가 된다.
참고자료
'Natural Language Processing > 딥 러닝을 이용한 자연어 처리 입문' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 원-핫 인코딩(One-Hot Encoding) (0) | 2021.03.15 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문]텍스트 전처리(text preprocessing) (0) | 2021.03.09 |
| [딥 러닝을 이용한 자연어 처리 입문]머신 러닝 워크플로우(Machine Learning Workflow) (1) | 2021.02.13 |
| [딥 러닝을 이용한 자연어 처리 입문]데이터 분석 패키지 (0) | 2021.02.13 |
| [딥 러닝을 이용한 자연어 처리 입문]실습 환경 만들기 (0) | 2021.02.09 |