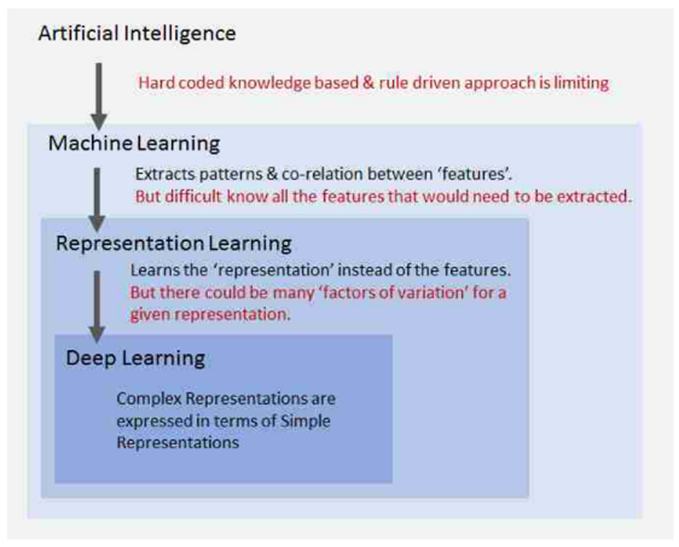
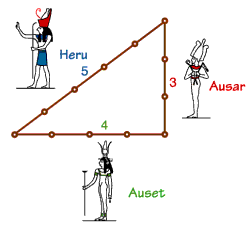
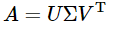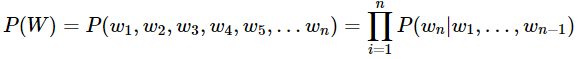Relationships between DL, representation learning, ML, AI Machine learning is a subfield of artificial intelligence. Deep learning is a subfield of machine learning, and so on. In case of ML, researchers assume that there’s sort of extracted features for a given input by human effort. But, in DL, we don’t need to invent this kind of features. Because every feature are learned automatically. We j..