728x90
01. 언어 모델(Language Model)이란?
언어 모델은 단어 시퀀스에 확률을 할당(assign)하는 일을 하는 모델이다.
단어 시퀀스에 확률을 할당하게 하기 위해서 가장 보편적으로 사용되는 방법은 언어 모델이 이전 단어들이 주어졌을 때 다음 단어를 예측하도록 하는 것이다.
언어 모델링(Language Modeling)은 주어진 단어들로부터 아직 모르는 단어를 예측하는 작업을 말한다. 즉, 언어 모델이 이전 단어들로부터 다음 단어를 예측하는 일은 언어 모델링이다.
- 주어진 이전 단어들로부터 다음 단어 예측하기
단어 시퀀스에 확률을 할당하기 위해서 가장 보편적으로 사용하는 방법은 이전 단어들이 주어졌을 때, 다음 단어를 예측하도록 하는 것이다. 이를 조건부 확률로 표현해보겠습니다. - A. 단어 시퀀스의 확률
하나의 단어를 w, 단어 시퀀스을 대문자 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은 다음과 같다.
P(W)=P(w1,w2,w3,w4,w5,...,wn) - B. 다음 단어 등장 확률
이제 다음 단어 등장 확률을 식으로 표현해자. n-1개의 단어가 나열된 상태에서 n번째 단어의 확률은 다음과 같다.
P(wn | w1,...,wn−1)
|의 기호는 조건부 확률(conditional probability)을 의미한다.
예를 들어 다섯번째 단어의 확률은 아래와 같다.
P(w5 | w1,w2,w3,w4)
전체 단어 시퀀스 W의 확률은 모든 단어가 예측되고 나서야 알 수 있으므로 단어 시퀀스의 확률은 다음과 같다.

02. 통계적 언어 모델(Statistical Language Model, SLM)
통계적 언어 모델이 통계적인 접근 방법으로 어떻게 언어를 모델링 하는지 살펴보자. 통계적 언어 모델(Statistical Language Model)은 줄여서 SLM이라고 한다.
- 조건부 확률
조건부 확률은 두 확률 P(A),P(B)에 대해서 아래와 같은 관계를 갖는다.
더 많은 확률에 대해서 일반화해보자.
4개의 확률이 조건부 확률의 관계를 가질 때, 아래와 같이 표현할 수 있다.
이를 조건부 확률의 연쇄 법칙(chain rule)이라고 힌다. 이제는 4개가 아닌 nn개에 대해서 일반화를 해보자.
- 문장에 대한 확률
문장 'An adorable little boy is spreading smiles'의 확률 P(An adorable little boy is spreading smiles)P(An adorable little boy is spreading smiles)를 식으로 표현해보자.
각 단어는 문맥이라는 관계로 인해 이전 단어의 영향을 받아 나온 단어이다. 그리고 모든 단어로부터 하나의 문장이 완성된다. 그렇기 때문에 문장의 확률을 구하고자 조건부 확률을 사용한다.
앞서 언급한 조건부 확률의 일반화 식을 문장의 확률 관점에서 다시 적어보면 문장의 확률은 각 단어들이 이전 단어가 주어졌을 때 다음 단어로 등장할 확률의 곱으로 구성된다.
조건부 확률을 문장에 적용해 보면 아래의 식과 같다. 문장의 확률을 구하기 위해서는 각 단어에 대한 예측 확률들을 곱해야 한다.
- 카운트 기반의 접근
SLM은 이전 단어로부터 다음 단어에 대한 확률을 구할 때, 카운트에 기반하여 확률을 계산한다.
An adorable little boy가 나왔을 때, is가 나올 확률인 P(is|An adorable little boy)를 구해보자.
그 확률은 아래와 같다. 예를 들어 기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데 그 다음에 is가 등장한 경우는 30번이라고 하지. 이 경우 P(is|An adorable little boy)P(is|An adorable little boy)는 30%이다.
하지만 카운트 기반으로 접근하려고 한다면 갖고있는 코퍼스(corpus). 즉, 다시 말해 기계가 훈련하는 데이터는 정말 방대한 양이 필요하다. 이로인해 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제인 희소 문제(sparsity problem)가 발생한다. 위 문제를 완화하는 방법으로 n-gram이나 스무딩이나 백오프와 같은 여러가지 일반화(generalization) 기법이 존재한다. 하지만 희소 문제에 대한 근본적인 해결책은 되지 못하였기 때문에 언어 모델의 트렌드는 통계적 언어 모델에서 인공 신경망 언어 모델로 넘어가게 됩니다.
03. N-gram 언어 모델(N-gram Language Model)
n-gram 언어 모델은 여전히 카운트에 기반한 통계적 접근을 사용하고 있으므로 SLM의 일종이다. 다만, 앞서 배운 언어 모델과는 달리 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법을 사용한다.
- 코퍼스에서 카운트하지 못하는 경우의 감소.
SLM의 한계는 훈련 코퍼스에 확률을 계산하고 싶은 문장이나 단어가 없을 수 있다는 점이다. 그리고 확률을 계산하고 싶은 문장이 길어질수록 갖고있는 코퍼스에서 그 문장이 존재하지 않을 가능성이 높다. 다시 말하면 카운트할 수 없을 가능성이 높다. 그런데 다음과 같이 참고하는 단어들을 줄이면 카운트를 할 수 있을 가능성이 높일 수 있다.
즉, 앞에서는 An adorable little boy가 나왔을 때 is가 나올 확률을 구하기 위해서는 An adorable little boy가 나온 횟수와 An adorable little boy is가 나온 횟수를 카운트해야만 했지만, 이제는 단어의 확률을 구하고자 기준 단어의 앞 단어를 전부 포함해서 카운트하는 것이 아니라, 앞 단어 중 임의의 개수만 포함해서 카운트하여 근사하자는 것이다. 이렇게 하면 갖고 있는 코퍼스에서 해당 단어의 시퀀스를 카운트할 확률이 높아진다. - N-gram
이 때 임의의 개수를 정하기 위한 기준을 위해 사용하는 것이 n-gram이다. n-gram은 n개의 연속적인 단어 나열을 의미한다. 갖고 있는 코퍼스에서 n개의 단어 뭉치 단위로 끊어서 이를 하나의 토큰으로 간주한다. n-gram을 통한 언어 모델에서는 다음에 나올 단어의 예측은 오직 n-1개의 단어에만 의존한다. 예를 들어 'An adorable little boy is spreading' 다음에 나올 단어를 예측하고 싶다고 할 때, n=4라고 한 4-gram을 이용한 언어 모델을 사용한다고 하자. 이 경우, spreading 다음에 올 단어를 예측하는 것은 n-1에 해당되는 앞의 3개의 단어만을 고려한다.

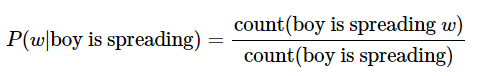
- N-gram Language Model의 한계
n-gram은 뒤의 단어 몇 개만 보다 보니 의도하고 싶은 대로 문장을 끝맺음하지 못하는 경우가 생긴다. 문장을 읽다 보면 앞 부분과 뒷부분의 문맥이 전혀 연결 안 되는 경우도 생길 수 있다. 따라서 전체 문장을 고려한 언어 모델보다는 정확도가 떨어질 수밖에 없다.
(1) 희소 문제(Sparsity Problem)
문장에 존재하는 앞에 나온 단어를 모두 보는 것보다 일부 단어만을 보는 것으로 현실적으로 코퍼스에서 카운트 할 수 있는 확률을 높일 수는 있었지만, n-gram 언어 모델도 여전히 n-gram에 대한 희소 문제가 존재한다.
(2) n을 선택하는 것은 trade-off 문제.
앞에서 몇 개의 단어를 볼지 n을 정하는 것은 trade-off가 존재한다.
n을 크게 선택하면 실제 훈련 코퍼스에서 해당 n-gram을 카운트할 수 있는 확률은 적어지므로 희소 문제는 점점 심각해진다. 또한 n이 커질수록 모델 사이즈가 커진다는 문제점도 있다.
n을 작게 선택하면 훈련 코퍼스에서 카운트는 잘 되겠지만 근사의 정확도는 현실의 확률분포와 멀어진다. 그렇기 때문에 적절한 n을 선택해야 한다. 앞서 언급한 trade-off 문제로 인해 정확도를 높이려면 n은 최대 5를 넘게 잡아서는 안 된다고 권장되고 있다.
참고 자료
728x90
'Natural Language Processing > 딥 러닝을 이용한 자연어 처리 입문' 카테고리의 다른 글
| [딥 러닝을 이용한 자연어 처리 입문] 토픽 모델링(Topic Modeling) (0) | 2021.03.23 |
|---|---|
| [딥 러닝을 이용한 자연어 처리 입문] 원-핫 인코딩(One-Hot Encoding) (0) | 2021.03.15 |
| [딥 러닝을 이용한 자연어 처리 입문]텍스트 전처리(text preprocessing) (0) | 2021.03.09 |
| [딥 러닝을 이용한 자연어 처리 입문]머신 러닝 워크플로우(Machine Learning Workflow) (1) | 2021.02.13 |
| [딥 러닝을 이용한 자연어 처리 입문]판다스 프로파일링(Pandas -Profiling) (0) | 2021.02.13 |